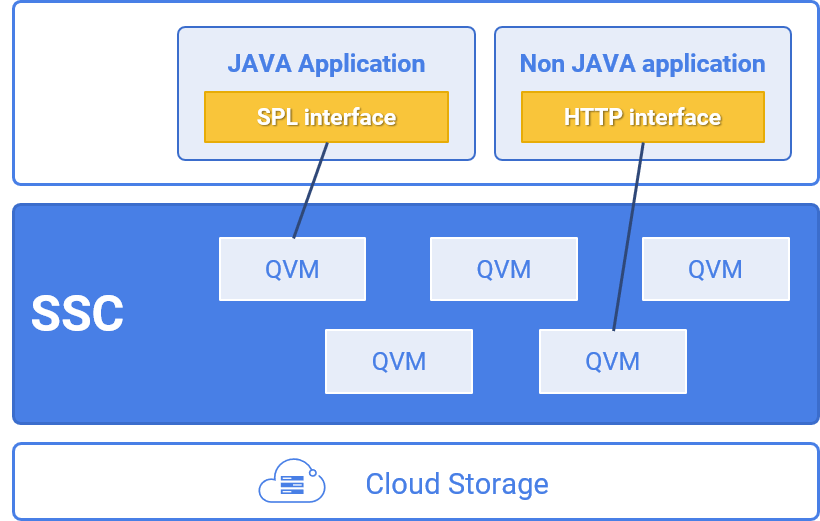
Scudata SPL Cloud (SSC) involves related components and concepts incl. QDB, QVM, QVA, QVS, SPL, etc.
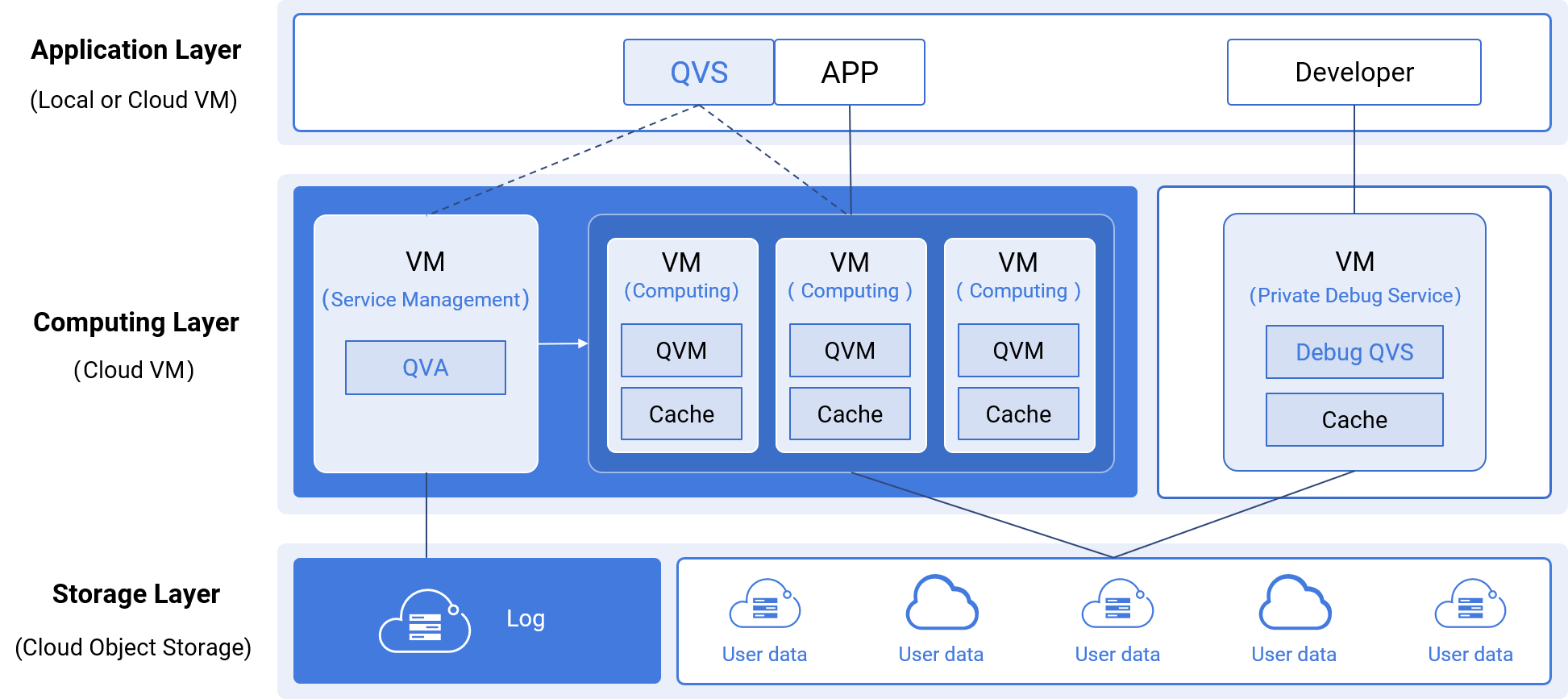
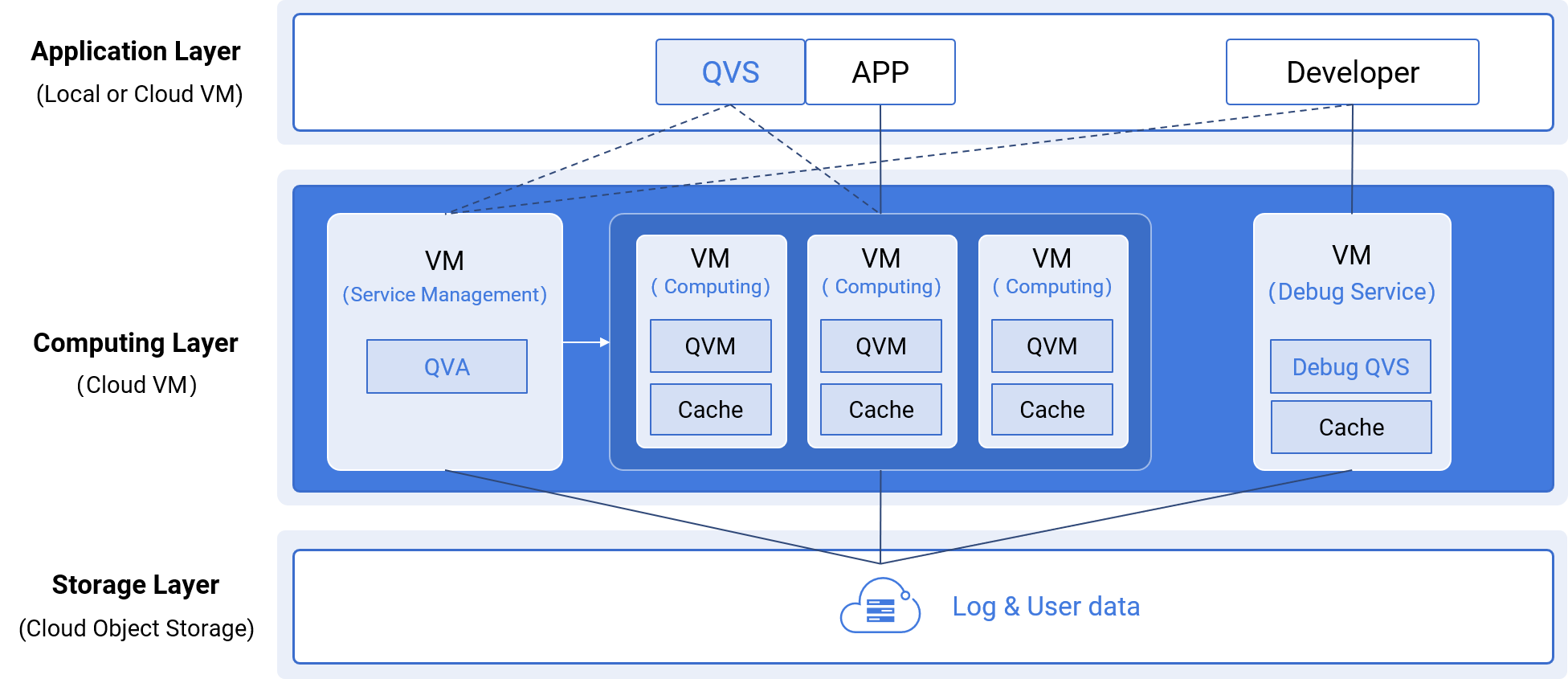
SSC uses files to store data, naturally supporting cloud object storage (files and objects correspond one by one), updating on a file basis.
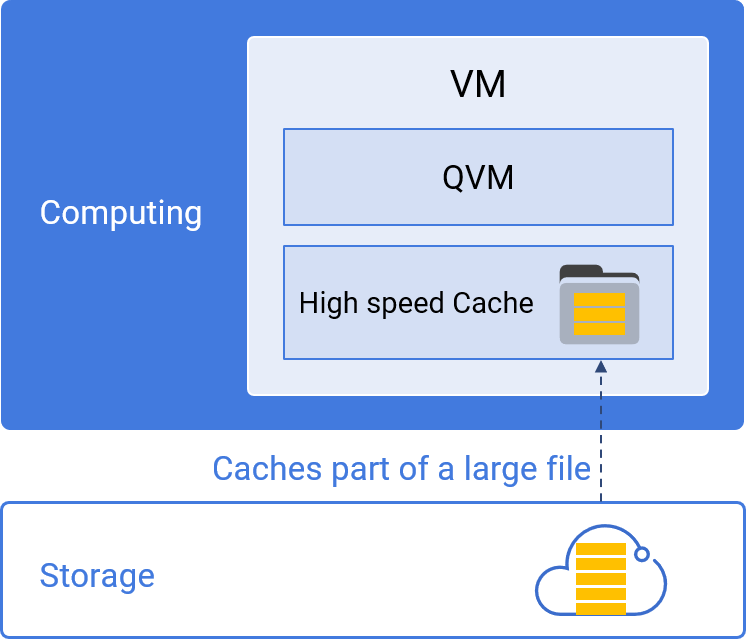
Directly using cloud object storage such as S3 for lower costs
Each virtual machine (computing resource) caches hot data for high-performance computing
Storage and computation are completely separated. Storage can be selected and managed by users, and QDB is responsible for data caching and computation
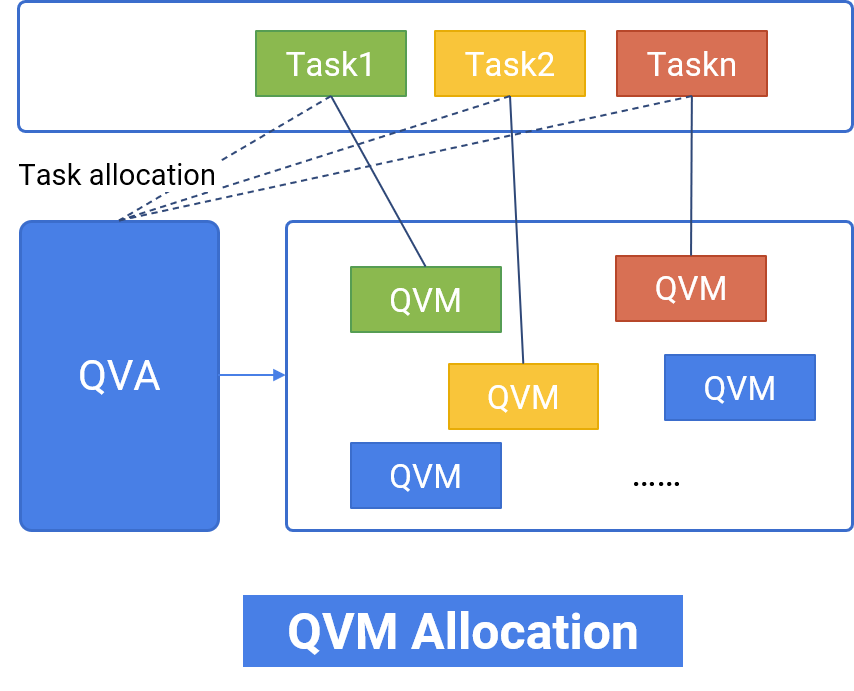
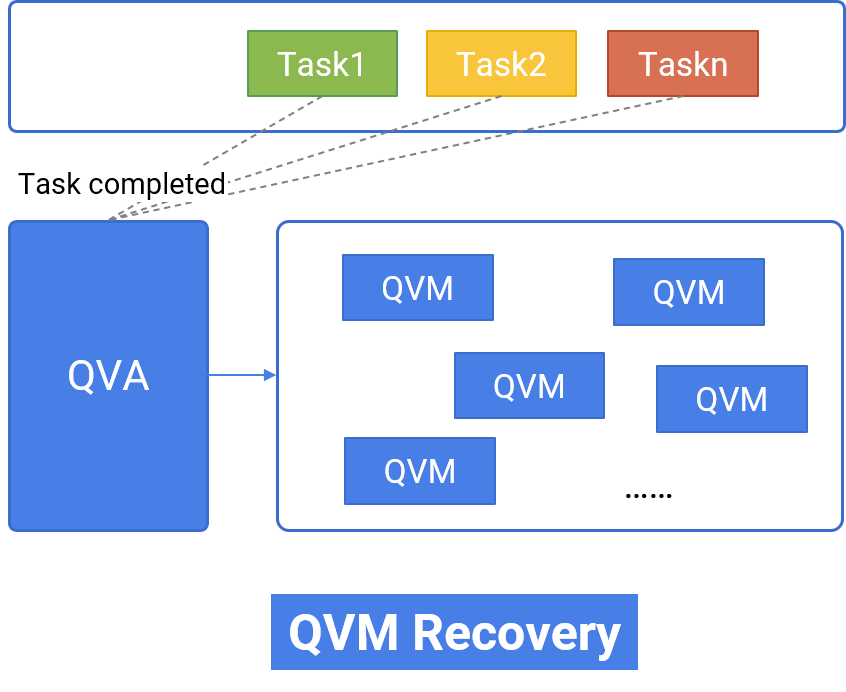
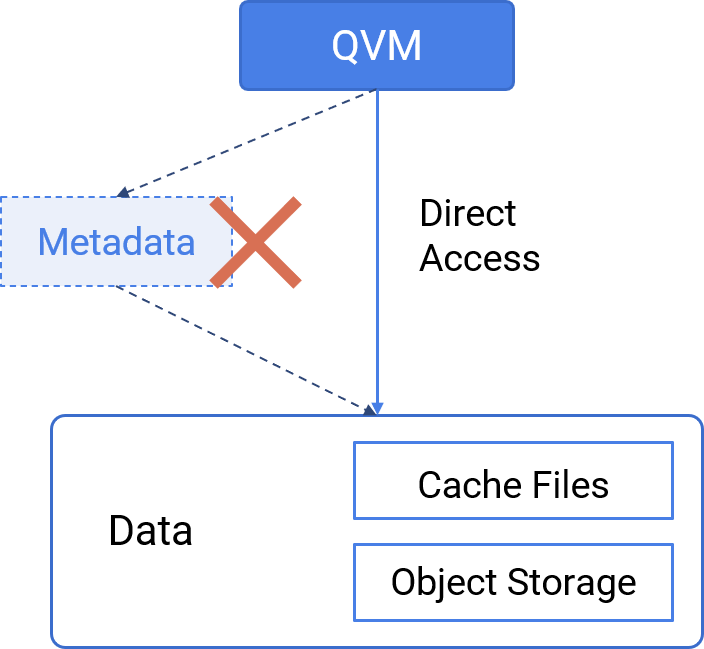
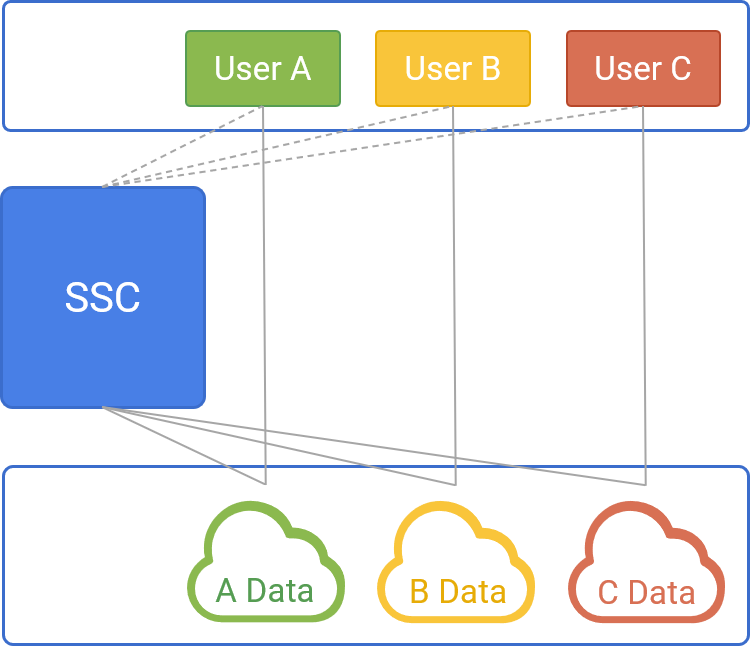
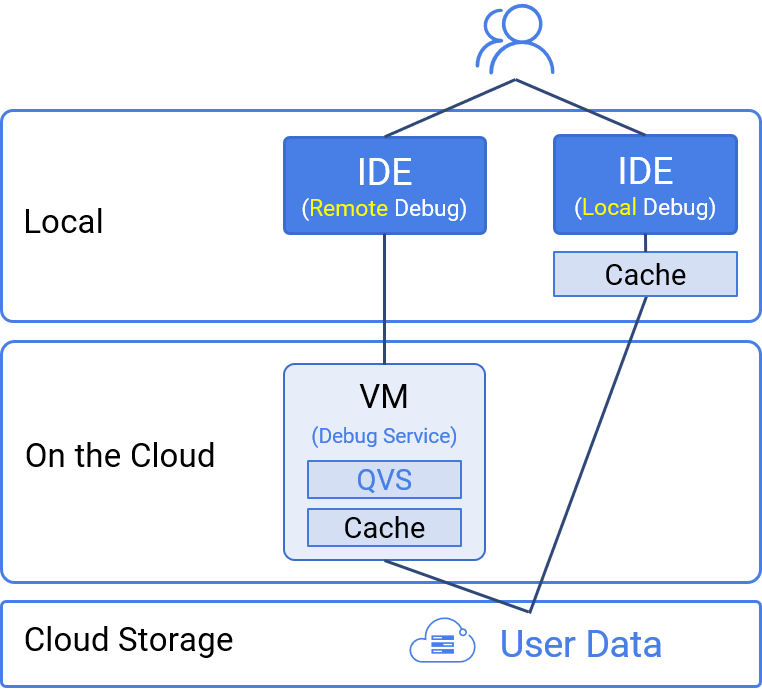
QVS supports private deployment
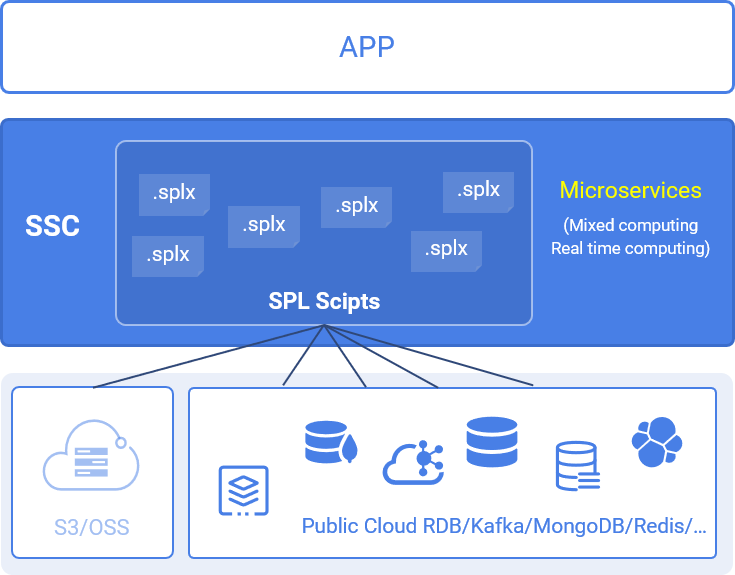
SPL supports integrated access of multiple data sources and mixed computing of multiple data sources
Real time access and processing of various cloud data can fully ensure the real-time nature of data and provide real-time data services for applications
With real-time data support and the real-time computing power of SPL, it can effectively support the implementation of microservices
SPL based on discrete dataset models can achieve performance improvements of several to hundreds of times compared to SQL; In another term, achieving the same performance consumes less computing resources
SPL syntax supports procedural calculations and provides richer data types and operations, making complex calculations simpler and lower code compared to SQL
SPL has more comprehensive functions and is simpler compared to SQL, Java, and Python, and can independently complete most data processing tasks, with a simple technology stack