
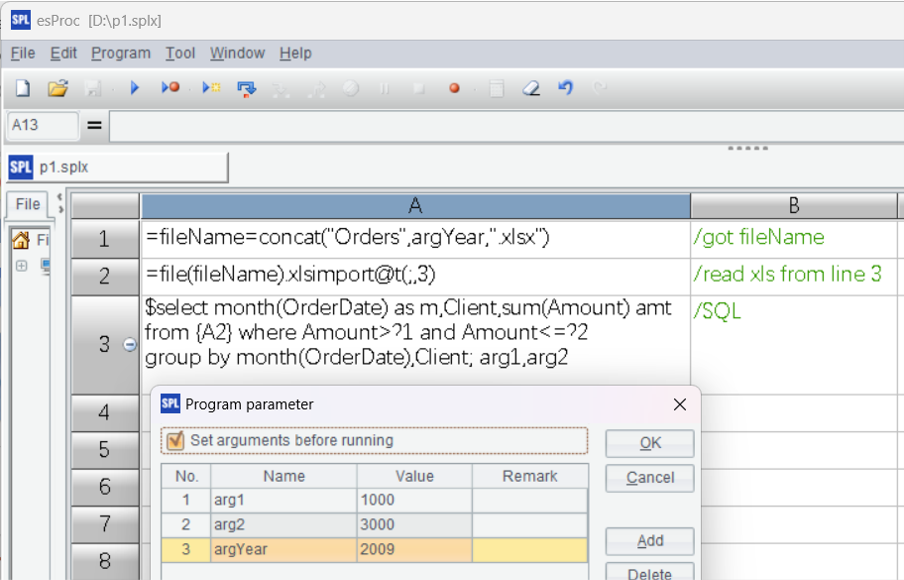


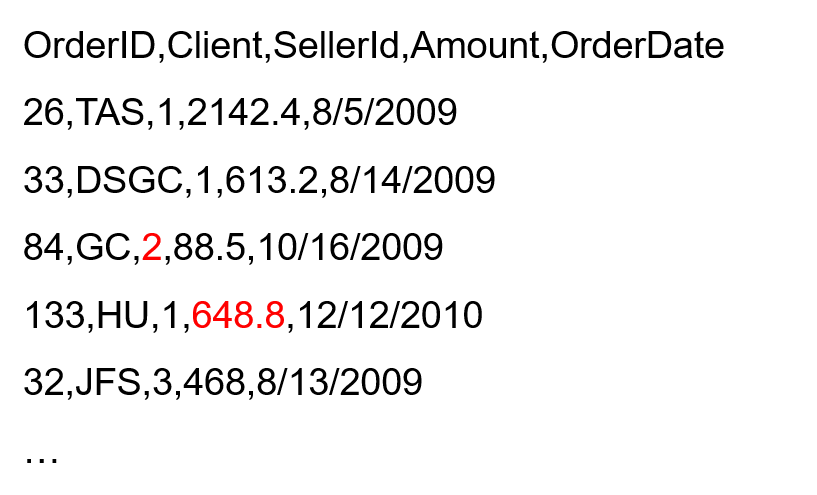
| A | B | C | |
| 1 | =old=file("Orders_old.csv").import@ct() | /Read old file | |
| 2 | =new=file("Orders_new.csv").import@ct() | /Read new file | |
| 3 | for old.len() | =cmp(old(A3),new(A3)) | /Compare records on same row in the two files in loop |
| 4 | =@|B3 | //Append comparison result to B4 | |
| 5 | =B4.count(~==0) | //Number of same rows | |
| 6 | =B4.count(~!=0) | //Number of different rows |
TDATE,CLOSING,OPENING,HIGHEST,LOWEST,VOLUME 1/2/2020,3085.2,3066.34,3098.1,3066.34,29.25B 1/3/2020,3083.79,3089.02,3093.82,3074.52,26.15B 1/6/2020,3083.41,3070.91,3107.2,3065.31,31.26B 1/7/2020,3104.8,3085.49,3105.45,3084.33,27.66B 1/8/2020,3066.89,3094.24,3094.24,3059.13,29.79B
| A | B | |
| 1 | =T("share_index.csv").sort(TDATE) | /Read file and sort it |
| 2 | =A1.group@i(CLOSING < CLOSING[-1]) | /Put neighboring records where prices rise to same group |
| 3 | =A2.max(~.count()) | /Get the max value |
| A | B | C | D | E | |
| 1 | Per_Code | in_out | Date | Time | Type |
| 2 | 1110263 | 1 | 2013-10-11 | 09:17:14 | In |
| 3 | 1110263 | 6 | 2013-10-11 | 09:17:14 | Break |
| 4 | 1110263 | 5 | 2013-10-11 | 11:38:21 | Return |
| 5 | 1110263 | 0 | 2013-10-11 | 11:43:21 | NULL |
| 6 | 1110263 | 6 | 2013-10-11 | 13:21:30 | Break |
| 7 | 1110263 | 5 | 2013-10-11 | 14:25:58 | Return |
| 8 | 1110263 | 2 | 2013-10-11 | 18:28:55 | Out |
| A | B | C | D | E | F | |
| 1 | Per_Code | Date | In | Out | Break | Return |
| 2 | 1110263 | 10/11/2013 | 09:17:14 | 18:28:55 | 11:37:00 | 11:38:21 |
| 3 | 1110263 | 10/11/2013 | 09:17:14 | 18:28:55 | 13:21:30 | 14:25:58 |
| A | B | |
| 1 | =T("attendance.xlsx").sort(Per_Code,Date,Time) | /Read data and sort it according to Per_Code, Date and Time |
| 2 | =A1.group@o((#-1)\7) | /Put every 7 records to same group according to Per_Code |
| 3 | =A2.(~([1,7,2,3,1,7,5,6])) | /Get ordered data of the current day from each group |
| 4 | =A3.conj( [~.Per_Code,~.Date] |~.(Time).m([1,2,3,4]) |[~.Per_Code,~.Date] |~.(Time).m([5,6,7,8])) | /Arrange data in a group into a sequence and concatenate groups |
| 5 | =create(Per_Code,Date,In,Out,Break,Return) | /Create an empty result set |
| 6 | >A5.record(A4) | /Insert data to result set |
| 7 | =file("result.xlsx").xlsexport@t(A5) | /Export result set to a new xls |
Sender: Melody<Melody@bus.emory.edu> Receiver: Susan<Susan@google.com> Date: 1/14/2020 Content: Do you yahoo!? SBC Yahoo!DSL - Dow only @29.95per month! Sender: Tom<Tom@163.com> Receiver: rose<rose@163.com> Date: 2/24/2020 Content: IMPORTANT NOTICE: The information in this email(and any attachments) is confidential. If you are not the intended recipient, you must not use or disseminate the …

| A | B | |
| 1 | =file("mail.txt").import@si() | /Read file as a set of rows |
| 2 | =A1.select(~!="") | /Remove empty rows |
| 3 | =A2.group@i(~=="Sender:") | /Group the set according to marker “Sender:”; each group is a record made up of an indefinite number of rows |
| 4 | =A3.new(~(2):Sender,~(4):Receiver,date(~(6)):Date ,~.to(8,).concat():Content) | /Organize the record having an indefinite number of rows into a standard one |
| 5 | =A4.select(like@c(Receiver,"*"+arg_name+*") && Date>arg_begin && Date<=arg_end ) | /Query records |
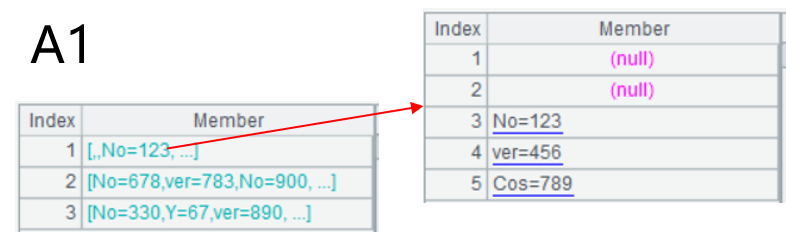
| A | B | C | D | E | |
| 1 | No=123 | ver=456 | Cos=789 | ||
| 2 | No=678 | ver=783 | No=900 | U=89 | |
| 3 | No=330 | Y=67 | ver=890 | Cos=311 | F=19 |
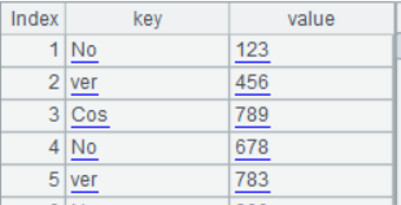
| A | B | |
| 1 | =file("keyvalue.xlsx").xlsimport@w() | /Load data as the form that cells in a row compose a small set and multiple small sets compose a larger set |
| 2 | =A1.conj() | /Concatenate the double-layer set into a single-layer set |
| 3 | =A2.select(~) | /Remove empty cells |
| 4 | =A3.(~.split("=")) | /Split each cell value into two parts according to = |
| 5 | =A4.new(~(1):key,~(2):value) | /Standardize records through naming part 1 key field and part 2 value field |
| 6 | =A5.select(key==arg_key) | /Perform query |
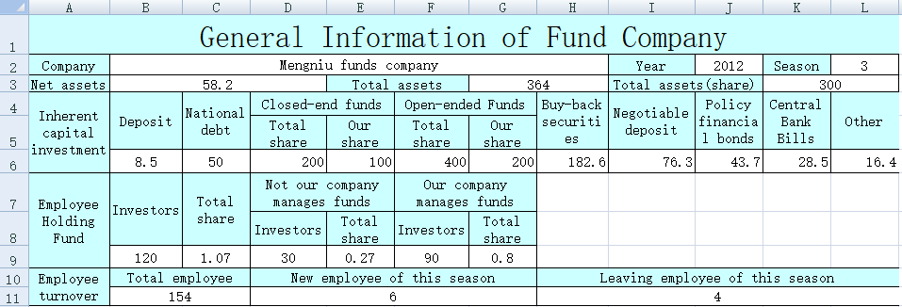
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file("e:/result.xlsx") | =A6.xlsopen() | ||||
| 7 | =C6.xlscell("B2",1;A1) | =C6.xlscell("J2",1;B1) | =C6.xlscell("L2",1;C1) | |||
| 8 | =C6.xlscell("B3",1;D1) | =C6.xlscell("G3",1;E1) | =C6.xlscell("K3",1;F1) | |||
| 9 | =C6.xlscell("B6",1;[A2:F2].concat("\t")) | =C6.xlscell("H6",1;[A3:E3].concat("\t")) | ||||
| 10 | =C6.xlscell("B9",1;[A4:F4].concat("\t")) | =C6.xlscell("B11",1;[A5:C5].concat("\t")) | ||||
| 11 | =A6.xlswrite(B6) | |||||
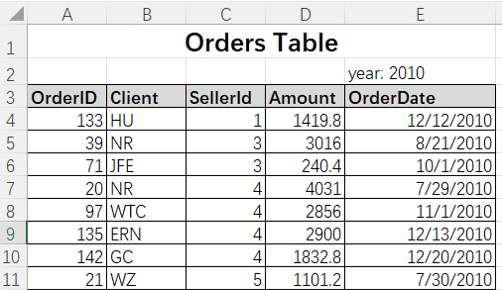
| A | B | |
| 1 | =Orders=json(httpfile("http://127.0.0.1:6868/api/orders").read()) | /Retrieve data from http |
| 2 | =Employees=T("d:/Emp.csv") | /Retrieve data from csv |
| 3 | =join@1(Orders:o,SellerId;Employees:e,EId) | /Association |
| 4 | =A3.group(e.Detp,o:dept.Client:client;sum(Amount):amt,count(1):cnt) | /Group & summarize |


